Sort of related to this (it wouldn't solve this issue, but I think it would improve overall ecosystem security & quality):
I do wish curl would split the curl backend protocols (http, ftp etc) into separate loadable modules so that we (downstream distro packagers) can reduce the total attack surface through packaging changes.
packaged separately as "libcurl-http" and "libcurl-ftp". Curl clients which only want HTTP would be set to depend on "libcurl-http" only, so the FTP support wouldn't even be on the system unless a package needs it.
There is a way to whitelist protocols already in curl (CURLOPT_PROTOCOLS(3)), but that requires modifying existing programs, and I think this could be used in addition.
There are lots of weird modules in curl (telnet, gopher, pop3 -- which don't get me wrong I think is great!) but they should not be a part of the default install of most Linux distros.
CVE-2013-0249 (in the qemu curl driver) was an exploit where the entire qemu process could be exploited because of a bug in curl's SASL driver, which could be invoked remotely by redirecting an http[s]:// URL initiated by qemu. This was fixed by changing qemu to use CURLOPT_PROTOCOLS(3) (as I detailed in my initial posting above) so that curl wouldn't try to redirect to SASL connections starting from an initial HTTP request.
IMHO it would be a lot better instead of having to change every possible curl client, to have some kind of distro-level limit on what code might be run by curl.
Of course I would still say if you're using curl, you really must use CURLOPT_PROTOCOLS or have a good excuse why not. The above change is just a backstop.
Would there still be a batteries-included curl package that some software/packages could depend on, if they don't want to worry about which protocol is supported? I'd hate for users throwing an FTP/whatever link at a tool that used to "just work" suddenly getting a "protocol not found" error.
It would have the added advantage of only needing load modules required for that particular command in action as well. If a module were vulnerable, it couldn’t be used as a jump point for some gadget in another module.
Yes you're quite right that you can do this when building curl:
./configure --disable-ftp
But then you end up with a libcurl that can never support FTP clients. However FTP is still a useful protocol in some circumstances, perhaps very limited these days, but still used. I think that it's better to expose this through a module system reflected into the distribution packages. It makes things much more visible.
In what way? Recompiling a few different binaries for various levels of usage (with/without whichever protocols needed) doesn't seem like an arduous task, especially for a distro. And the docs on how to do it from the curl project are very clear and "visible". I'm not sure how any module system would improve on this.
In fact, it seems like it would disimprove purely by virtue of not being idiomatic - compile flags are a familiar and straightforward, well-known approach.
Your solution is multiple copies of libcurl all over the place, all compiled in different ways, probably different versions, and that's supposed to be more secure and maintainable?
More secure: not more, but equally. More maintainable: infinitely. This is how software is being built today in secure environments anyway, since you need to own the supply chain.
I would be very miffed if my application suddenly autodetected a proxy (whether it-dept or adversary installed) and decided to break the end-to-end security property of TLS that my app relied on. But maybe in the best case this would have been limited to tunneling (HTTP CONNECT) proxies that pass TLS traffic as-is?
But I guess this is just speculation now that it wasn't implemented.
Interesting choice to have a set of FAQ in your docs without also providing answers to them. I suppose the term FAQ does sort of imply it is just the "questions".
The core doesn't have any dependencies, but it can support a bunch of different modules. Most notably is JavaScript to execute PAC files (WebKit, mozjs, etc.)
For macOS it calls "JSEvaluateScript(this->jsctx, str, NULL, NULL, 1, NULL)".
Obviously this kind of stuff is useful for some people, but yeah ... I'd be hesitant too; not because whether libproxy might be good or bad, but rather the nature of what it does (execute code).
Sooo does it implement http ? Coz having lib to search for proxy (it supports few http auto config methods) with its own implementation of http to use in http library would be kinda silly
Apple and MSFT build their own replacements for TLS and use those, others? part of a trend to replace and extend GPL software, and control critical network functions on their platforms ?
but then, others seem to want to make TLS, too ?
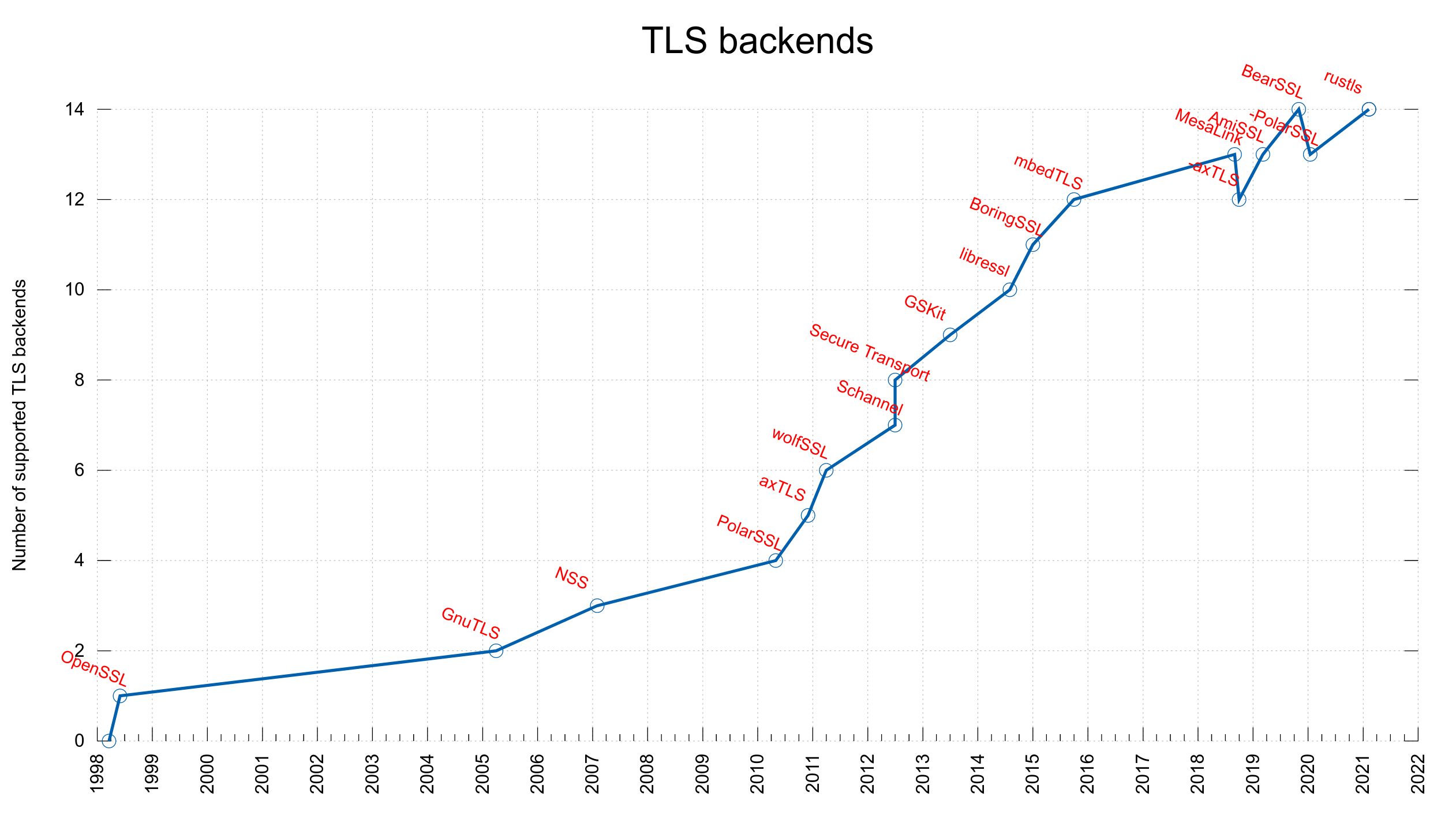
[ Windows native SSL/TLS, schannel ]
[ Apple OS native SSL/TLS, secure-transport ]
[ GNU TLS ]
[ mbedtls, wolfssl, mesalink, bearssl, rust-tls, nss]
Exactly, everything’s a trade-off. And the trade-offs will be different for a very widely used system package like curl compared to, say, a small in-house ERP system or low-traffic website.
For a generally usable implementation, libproxy needs to be able to process proxy auto-config (PAC) files, which are small (or not so small) Javascript programs. These programs are expected the parse the URL and decide which proxy server to use (or a direct connection). It's not declarative at all.
True but curl wouldn't need to implement a particularly optimised JavaScript runtime to handle PAC programs, there would be no point in e.g. bundling V8 or ChakraCore with it.
In my general experience, "System Admins" have a security-first mindset along with years of focusing on how to maintain a secure system AND blessing from management to be slower for end-product reliability and security of business assets/data.
Developers, *who can certainly have this mindset and skill set as well*, are typically forced to be more business-oriented with management-dictated objectives/deadlines that more strictly limits their ability to invest the time, so you get "the best I can do in the allotted sprint/deadline time minus the other committed work I need to do".
So inevitably the application will let something through, and it becomes to System Admins' responsibility to protect the company... And that seems to be okay with most businesses.... Developers can move quick fast and dirty, and the operations/admins will try to limit the scope of the blast.
It adds several hours or days of work for a developer to add secret storing/retrieval/rotation compared to just hard-coding a key in the environment, so if they have 2 days to implement a feature, they are not going to spend 2 days implementing extra safeguards unless someone speaks up and pushes back (and the other side relents)
Which is why DevOps, sorry system admins, then have automated tooling for detecting those kind of workarounds, and then we get a sad developer that has to fix a broken pipeline deployment.
In case of places that take security seriously that is.
I wrote https://www.npmjs.com/package/esbuild-copy-static-files only using the Node standard library. It's a small library to make copying static files with esbuild more efficient, it avoids copying files that didn't change. It's useful for watching and copying files in development.
It was funny writing the readme file though where "No 3rd party dependencies" ended up being called out as a feature. I wouldn't have thought to call that out as a primary feature in any other language's ecosystem.
I’ve written a library with zero production dependencies. Of course I have Jest as a development dependency which pulls in all sorts of stuff. It would be difficult to make a zero-dependency library. As for not having production libraries, this was my experience:
1. Using the https module directly was more work than I expected, especially with error handling. This made me really look forward to the new Fetch API coming out.
2. No CLI parser. Its not like parsing args is a LOT of work - but its also something that is already solved and having to write support for that directly was a bummer
3. No logging library. This one was pretty easy. Create a little class with logging levels. Again this is something that is very common that would have been nice to use a package for.
What you describe is exactly why people use dependencies. You just decided to trade your time for the noble act of having “no production dependencies”, while one of the 275 modules installed by Jest (real number) stole your production secrets anyway.
As for point 2, Node 18.1 I think just introduced a native argument parser.
They still get run on a developer’s machine most of the time and are at least installed there where they can run arbitrary code on install. And there are juicy secrets beyond just production server secrets sitting on your laptop.
Lots of production environments tend to sit on latest LTS. v18 _just_ hit LTS, up to last month it was v16. Those weren't really an option for all these projects until then.
Yes, my library absolutely has to support the LTS version of Node, and I run the tests against all supported versions to ensure compatibility. So, one day I can use the nice things people are mentioning, but it will be years from now.
> I've written a library with zero production dependencies. Of course I have Jest as a development dependency which pulls in all sorts of stuff. It would be difficult to make a zero-dependency library.
That really depends on what your expectations and goals are. You mention Jest but as it's a test dependency then security is not a major concern, and thus it's ok to just vend the source code into your project trees.
No, the levels are not useless, far from it. Even if you just print to stdout, prefixing each line with a (maybe colored?) level info is very useful. Also, if later you decide to use xyz format, it is trivial to implement this. Changing all logging calls? Not so much.
To answer your question, the levels are important for both regular usage and debugging when something goes wrong. I create a number of debug/info/warning/error log messages throughout the tool and allow the desired level of logging to be set as a CLI argument - or even run in silent mode if desired.
In reverse I've seen a banking apps pull in a gigabyte of node dependencies and am thinking there's no possible way they'll ever be able to validate the security of everything.
On most of the projects I am involved with, if the modules haven't been cleared for use, the CI/CD pipeline will fail, regardless of working on dev's machine.
{kind=link}
I do wish curl would split the curl backend protocols (http, ftp etc) into separate loadable modules so that we (downstream distro packagers) can reduce the total attack surface through packaging changes.
For example, we could have:
packaged separately as "libcurl-http" and "libcurl-ftp". Curl clients which only want HTTP would be set to depend on "libcurl-http" only, so the FTP support wouldn't even be on the system unless a package needs it.There is a way to whitelist protocols already in curl (CURLOPT_PROTOCOLS(3)), but that requires modifying existing programs, and I think this could be used in addition.
There are lots of weird modules in curl (telnet, gopher, pop3 -- which don't get me wrong I think is great!) but they should not be a part of the default install of most Linux distros.